Introdução
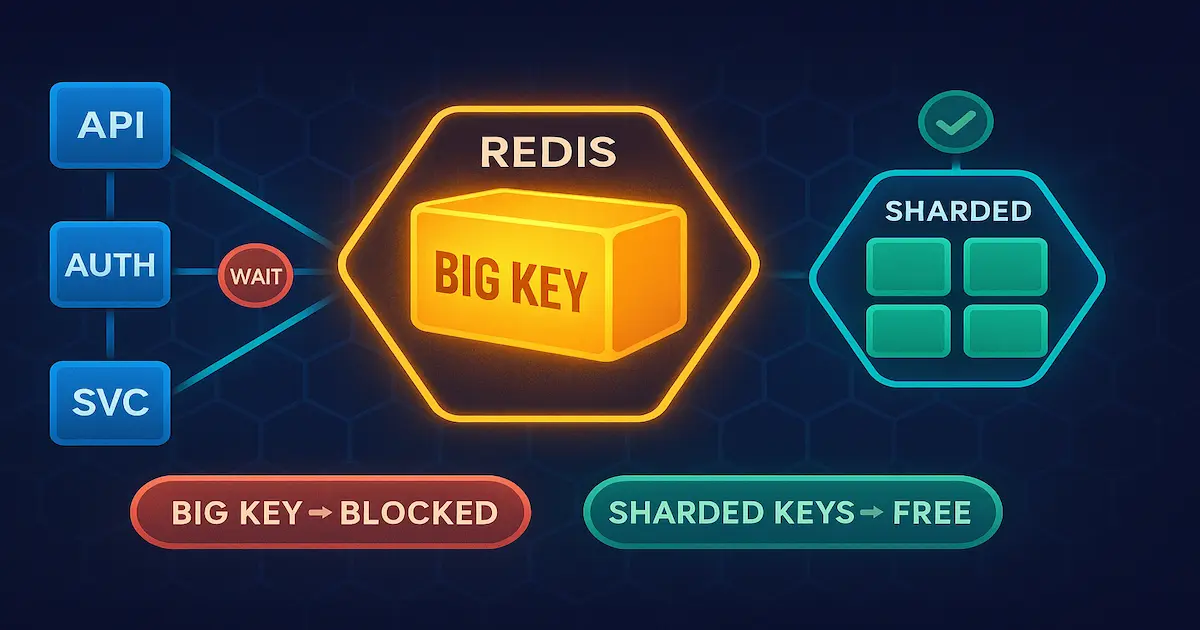
Se você usa Redis em um ambiente compartilhado — seja uma instância usada por múltiplos microserviços, múltiplos times ou múltiplos tenants — uma única chave grande pode degradar o desempenho de todos os outros consumidores ao mesmo tempo. Não é exagero: é como o Redis funciona internamente, e ignorar esse comportamento em produção custa caro.
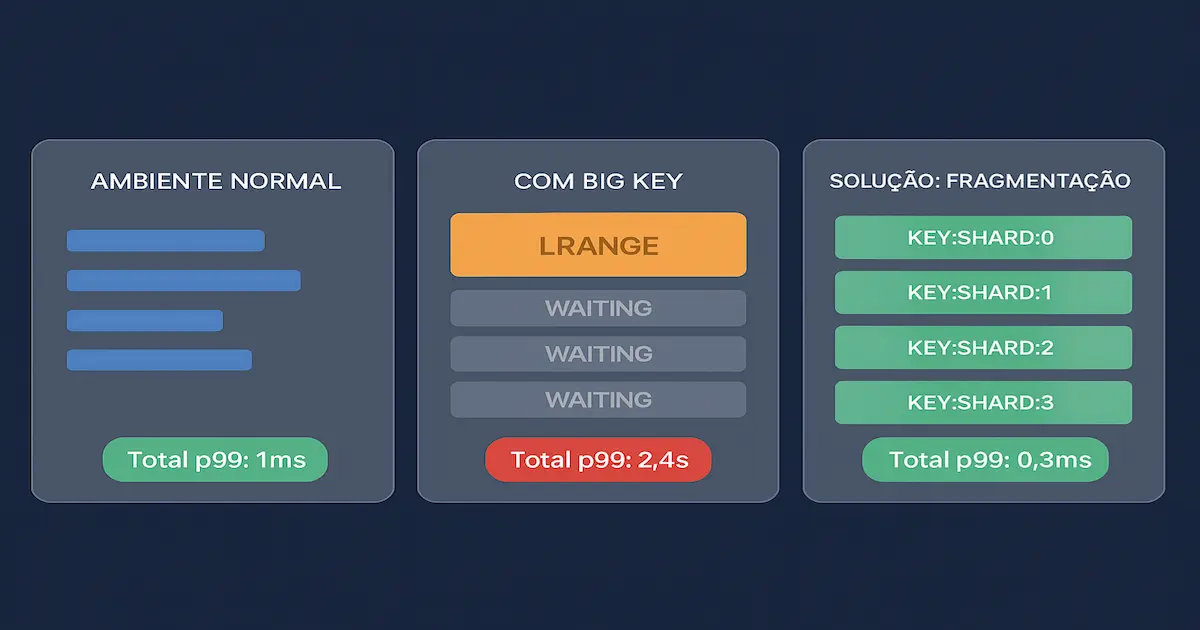
O problema das chaves grandes (big keys) no Redis existe porque o servidor é single-threaded para operações de dados. Quando um comando acessa ou manipula uma chave que contém centenas de megabytes — seja uma lista com 500 mil elementos, um hash com 200 mil campos ou um string binário de 50 MB — o event loop inteiro fica bloqueado processando essa operação. Todos os outros clientes, de outros serviços completamente diferentes, ficam esperando na fila. Em ambientes compartilhados isso é fatal.
Neste artigo vou mostrar o que caracteriza uma chave grande no Redis, por que o impacto é amplificado em ambientes multi-tenant, como detectar big keys em produção, e as estratégias concretas para eliminar ou mitigar o problema — com exemplos em C# usando StackExchange.Redis.
O que é uma “Big Key” no Redis
O Redis não tem um limite fixo que define quando uma chave é “grande”. A comunidade e a documentação oficial usam o termo big key para descrever chaves cujo custo de processamento ou memória é desproporcional em relação ao workload geral da instância.
Na prática, os limites que costumam surgir como referência são:
| Tipo de Dado | Considerado “grande” a partir de |
|---|---|
| String / Binary | > 5 MB |
| List | > 10.000 elementos ou > 10 MB |
| Hash | > 10.000 campos |
| Set | > 10.000 membros |
| Sorted Set | > 10.000 membros |
| Stream | > 10.000 mensagens pendentes |
Esses números não são absolutos — dependem do hardware, da versão do Redis e do padrão de acesso. Mas são referências sólidas para alertas de monitoramento.
ℹ️ Informação: O Redis 7.0+ introduziu melhorias nas estruturas de dados internas (como Listpack substituindo ZipList), o que mudou ligeiramente os limiares de quando estruturas “promovem” para representações maiores. O conceito de big key, no entanto, permanece o mesmo.
Diferença entre chave grande e chave quente
É comum confundir big key com hot key. São problemas diferentes:
- Big key: chave com muito volume de dados — o problema é o custo de CPU/memória para processar o dado.
- Hot key: chave acessada com altíssima frequência — o problema é a contenção no slot de hash (relevante em Redis Cluster).
Um artigo pode ter ambos os problemas ao mesmo tempo, mas as soluções são distintas. Este artigo foca em big keys.
Como o Redis Processa Comandos (e por que isso importa)
Para entender o impacto de big keys, é preciso entender como o Redis executa comandos. O Redis usa um event loop single-threaded para processar operações de dados. Isso significa:
- O servidor recebe um comando de um cliente.
- O event loop executa o comando até o fim antes de processar qualquer outro.
- Somente depois o próximo comando da fila é processado.
Essa arquitetura é uma das razões pelo qual o Redis é tão rápido para operações simples: sem locks, sem context-switching entre threads. O custo é que uma operação lenta bloqueia tudo.
| |
⚠️ Atenção: Comandos como
LRANGE key 0 -1,SMEMBERS key,HGETALL keyeKEYS *são O(N) — o custo cresce linearmente com o tamanho da estrutura. Em uma chave com 500 mil elementos, isso pode levar segundos.
O modelo de I/O do Redis não é bloqueante — mas o processamento é
É importante separar dois conceitos:
- I/O: o Redis usa multiplexação de I/O (epoll/kqueue), então aceitar conexões e ler dados de rede é não bloqueante.
- Processamento de comandos: a execução do comando em si é single-threaded e bloqueante para os outros clientes.
O Redis 6.0 introduziu threads de I/O para leitura e escrita de rede, mas a execução dos comandos ainda é single-threaded no thread principal. O problema das big keys não foi resolvido por essa mudança.
Impacto em Ambientes Compartilhados
Em um ambiente onde uma única instância Redis serve múltiplos microserviços ou múltiplos tenants de um SaaS, o impacto de uma big key é amplificado porque:
1. A latência afeta todos, não só o culpado
Se o serviço de relatórios lê uma chave com 300 mil registros toda hora, isso introduz picos de latência para o serviço de autenticação, o serviço de notificações e qualquer outro que compartilhe a mesma instância — mesmo que esses serviços estejam funcionando perfeitamente.
2. O consumo de memória é disputado
Redis mantém todos os dados em memória. Uma big key que ocupa 500 MB comprime o espaço disponível para todos os outros tenants. Quando o Redis atinge maxmemory, inicia a política de eviction (expulsão de chaves), que pode descartar dados críticos de outros serviços.
3. Operações de snapshot e replicação ficam mais lentas
Quando o Redis gera um RDB snapshot (persistência) ou replica dados para um replica, big keys aumentam o tempo do fork() e o tamanho do arquivo. Em instâncias cloud (AWS ElastiCache, Azure Cache for Redis), isso pode causar falhas de replicação ou penalidades de performance durante a sincronização.
4. Dificuldade de debug e rastreabilidade
Em um ambiente compartilhado, identificar quem criou a big key e qual serviço é o responsável exige instrumentação cuidadosa. Sem namespacing adequado nas chaves, rastrear a origem do problema pode levar horas.
Como Detectar Big Keys em Produção
O Redis oferece ferramentas nativas para detectar big keys. Veja as principais abordagens:
redis-cli –bigkeys
O comando mais simples para uma varredura inicial:
| |
A saída mostra as maiores chaves por tipo de dado. O problema é que esse comando usa SCAN internamente e pode demorar em instâncias grandes. Em produção, prefira executá-lo em horários de menor carga.
MEMORY USAGE — verificação pontual
Para checar o tamanho de uma chave específica:
| |
SCAN + MEMORY USAGE — varredura automatizada em C#
Para monitoramento programático com StackExchange.Redis:
| |
📂 Código Fonte: O exemplo completo está disponível no repositório de exemplos do blog:
BlogSamples/Cache/Redis/
📝 Exemplo: Em um ambiente com 2 milhões de chaves, uma varredura com
pageSize = 500epattern = "relatorio:*"limita o escopo apenas ao namespace problemático, reduzindo o tempo de varredura de horas para minutos.
Redis Latency Monitoring
Para detectar o impacto em tempo real, ative o monitoramento de latência:
| |
Estratégias para Evitar Big Keys
Detectar o problema é o primeiro passo. Resolver é mais interessante. Existem quatro abordagens principais:
1. Fragmentação de dados (Sharding)
Em vez de uma única chave grande, distribuir os dados em múltiplas chaves menores usando um campo de particionamento:
| |
2. Serialização eficiente com compressão
Um dos maiores culpados por strings grandes é a serialização ingênua de objetos complexos. Trocar JSON por um formato binário + compressão reduz dramaticamente o tamanho:
| |
💡 Dica: Compressão GZip típica reduz payloads JSON em 60–80%. Um objeto de 5 MB pode cair para 800 KB — o que muda a classificação de “big key” para um tamanho gerenciável. Mas atenção: compressão tem custo de CPU, avalie o trade-off para dados acessados com alta frequência.
3. TTL obrigatório para chaves de cache
Chaves sem TTL em ambientes compartilhados tendem a acumular dados indefinidamente. Implemente uma política de TTL obrigatória:
| |
4. Namespacing e segregação por tenant
Em ambientes multi-tenant, use prefixos obrigatórios para identificar a origem das chaves. Isso facilita o diagnóstico e permite políticas de limpeza seletivas:
| |
Exemplo Prático
Vou mostrar um cenário real: um serviço de relatórios que carregava todos os registros de transações do mês em uma única chave Redis para “cache” — e estava derrubando o desempenho dos outros serviços no mesmo cluster.
O problema original
| |
Esse código cria uma chave que pode ter 80 MB no Redis, sem TTL, e é lida inteira a cada acesso. Cada leitura bloqueia o event loop por centenas de milissegundos.
A solução refatorada
| |
Com essa abordagem, cada chave passa de 80 MB para ~30 KB. O event loop é liberado em microssegundos, e os outros serviços compartilhados deixam de sofrer latência por conta do serviço de relatórios.
Dicas e Boas Práticas
Defina limiares de alerta no CI/CD: antes de um deploy, verifique se novos padrões de chave respeitam os limites de tamanho. Uma pipeline de testes de carga com
redis-cli --bigkeyspode prevenir o problema antes de chegar à produção.Use TTL em absolutamente todas as chaves: em ambientes compartilhados, uma chave sem TTL é uma chave que vai crescer indefinidamente. Configure
maxmemory-policy allkeys-lruno Redis para que, mesmo que alguma chave escape sem TTL, o Redis possa descartá-la quando necessário.Nunca use
KEYS *em produção: o comandoKEYSbloqueia o Redis enquanto varre todo o keyspace. Use sempreSCANcomMATCHeCOUNTpara varreduras iterativas e não bloqueantes. OStackExchange.Redisexpõe esse comportamento através deIServer.KeysAsync().Monitore
redis-cli --latency-history: latências acima de 50ms recorrentes são sinal de big keys ou hot keys. Configure alertas de latência no Redis e correlacione com os padrões de chave que estão sendo acessados no momento.Separe workloads em instâncias distintas quando possível: se um serviço de relatórios inevitavelmente precisa de chaves grandes, isole-o em uma instância Redis dedicada. O custo de uma instância extra é muito menor que o impacto de latência nos serviços críticos de um ambiente compartilhado.
Prefira estruturas nativas do Redis ao invés de strings JSON grandes: um
HASHcom 1.000 campos é mais eficiente que umSTRINGcom um JSON de 1.000 propriedades. O Redis pode acessar campos individuais do hash sem deserializar a estrutura toda, economizando CPU e memória.Revise o design ao usar Redis como banco de dados: Redis é excelente como cache de curta duração, pub/sub e contadores. Quando começa a receber coleções completas de entidades para “persistência temporária”, é um sinal de que o design precisa ser revisado — provavelmente um banco relacional ou documento é a ferramenta certa para aquele dado.
Resumo Objetivo
- Big key no Redis — chave cujo volume de dados é desproporcional ao workload; limites práticos são 5 MB para strings, 10.000 elementos para listas/hashes/sets. A partir desses valores, operações O(N) bloqueiam o event loop por centenas de milissegundos.
- Event loop single-threaded — o Redis processa um comando por vez no thread principal (mesmo no Redis 6.0+ com I/O threads). Uma big key bloqueia todos os outros clientes da instância enquanto é processada.
- Ambientes compartilhados — em instâncias Redis usadas por múltiplos microserviços ou tenants, uma big key criada por um único serviço introduz latência para todos os outros, independentemente do seu comportamento.
- Comandos O(N) perigosos —
LRANGE key 0 -1,SMEMBERS key,HGETALL key,KEYS *eSUNIONSTOREsão os principais vetores de bloqueio quando aplicados a chaves grandes. Prefira variantes paginadas comoHSCAN,SSCANeZSCAN. - Detecção em produção —
redis-cli --bigkeysrealiza varredura por tipo;MEMORY USAGE key SAMPLES Nretorna o tamanho exato em bytes incluindo overhead;LATENCY LATESTidentifica comandos com latência anômala. - Fragmentação como solução — dividir uma big key em múltiplas chaves menores usando sharding por campo elimina o bloqueio e permite paralelismo na leitura. Um hash com 100.000 campos pode ser dividido em 16 shards de ~6.250 campos cada.
- TTL obrigatório — toda chave em ambiente compartilhado deve ter expiração. A ausência de TTL é a principal causa de acúmulo de big keys em produção. Configure
maxmemory-policy allkeys-lrucomo rede de segurança.
Leia Também
- Gargalo em Banco de Dados: Mensageria e Paginação — estratégias para resolver gargalos de escrita e leitura com mensageria e paginação eficiente no EF Core 8+.
- .NET Worker e Background Service: Processamento de Alto Volume — como processar grandes volumes de dados em background sem sobrecarregar os serviços principais.
- Programação Assíncrona em C#: async/await e Threads — fundamentos de programação assíncrona em C# para evitar bloqueios em operações de I/O, incluindo acesso a caches.
- Paginação em APIs REST com C# e EF Core: Guia Prático — padrões de paginação para evitar retornar grandes volumes de dados de uma vez.
Referências
- Redis Big Keys — Documentação Oficial — especificações de tipos de dados e comportamento interno do Redis por versão.
- Redis Memory Optimization — Best Practices — guia oficial de otimização de memória no Redis, cobrindo encoding interno de estruturas de dados.
- StackExchange.Redis — Documentação — documentação da biblioteca cliente .NET para Redis, incluindo uso de SCAN e MEMORY USAGE.
- Redis Latency Problems — Troubleshooting Guide — guia oficial de diagnóstico de latência no Redis, com foco em comandos bloqueantes.
- Anti-Patterns in Redis Usage — Redis Labs Blog — anti-padrões comuns de uso do Redis identificados pela equipe da Redis Ltd., incluindo big keys e hot keys.
- Redis SCAN command — documentação do comando SCAN com exemplos de varredura não bloqueante para uso em produção.
Ao comentar, você concorda com nossa Política de Privacidade, Termos de Uso e Política de Exclusão de Dados.