Introdução
Se você trabalha com tecnologia, já percebeu: todo dia surge uma sigla nova no universo da inteligência artificial. LLM, RAG, MCP, Agent, Skill, Modelo — a lista cresce mais rápido do que qualquer profissional consegue acompanhar. E o pior não é a quantidade de termos. O pior é que esses termos aparecem em reuniões, em decisões de arquitetura, em descrições de vagas e em roadmaps de produto — e muitas vezes ninguém para para explicar o que cada um realmente significa.
Este artigo existe para resolver isso. Ele foi escrito para profissionais de TI que já têm experiência com desenvolvimento, infraestrutura ou gestão, mas que não tiveram tempo (ou oportunidade) de mergulhar nos conceitos fundamentais da IA moderna. Não é um tutorial de implementação. É um mapa conceitual — uma referência que você pode consultar quando precisar entender o que é cada peça e como elas se encaixam.
Ao final da leitura, você vai entender:
- O que é IA, e como ela se divide em camadas (Machine Learning, Deep Learning, IA Generativa)
- O que é um Modelo de IA e o que significa ter 7 bilhões ou 405 bilhões de parâmetros
- O que é LLM e por que ele é o motor por trás de ferramentas como ChatGPT, Copilot e Claude
- O que é RAG e por que ele resolve um dos maiores problemas dos LLMs
- O que é um Agente de IA e como ele se diferencia de um chatbot
- O que é uma Skill e como ela se diferencia de uma ferramenta
- O que é MCP e por que ele está sendo chamado de “o USB da inteligência artificial”
- Quais são os principais players do mercado e em que cada um se destaca
Vamos direto ao ponto.
Pré-requisitos
- Familiaridade básica com desenvolvimento de software ou infraestrutura de TI
- Nenhum conhecimento prévio sobre IA é necessário — o artigo parte do zero
O que é Inteligência Artificial
Inteligência Artificial (IA) é um campo da ciência da computação dedicado a criar sistemas capazes de realizar tarefas que normalmente exigiriam inteligência humana. Reconhecer padrões em imagens, entender linguagem natural, tomar decisões baseadas em dados, gerar texto e código — tudo isso cabe sob o guarda-chuva da IA.
Mas IA é um termo amplo. Pense nele como uma boneca russa — dentro dele existem subáreas progressivamente mais específicas:
| |
- Machine Learning (ML): Sistemas que aprendem a partir de dados, sem serem explicitamente programados para cada situação. Exemplo: um modelo de detecção de fraudes que aprende padrões a partir de transações históricas.
- Deep Learning (DL): Subconjunto do ML que usa redes neurais com muitas camadas (“profundas”). É a base dos avanços recentes em reconhecimento de imagem, voz e linguagem.
- IA Generativa (GenAI): Subconjunto do Deep Learning especializado em criar conteúdo novo — texto, imagem, código, áudio, vídeo. É aqui que moram o ChatGPT, o Copilot, o Claude e o Gemini.
💡 Dica: Quando alguém fala “IA” no contexto corporativo atual, na maioria das vezes está se referindo a IA Generativa — especificamente a modelos de linguagem (LLMs). É importante saber que IA é muito mais do que isso, mas o hype do momento está concentrado nessa camada.
A diferença prática entre IA tradicional e IA moderna é simples: a IA tradicional funciona com regras pré-definidas (se X, então Y). A IA moderna aprende padrões a partir de dados e generaliza para situações que nunca viu antes. Os dois modelos coexistem — e cada um tem seu lugar.
O que é um Modelo de IA
Quando alguém menciona “modelo” no contexto de IA, está falando de um artefato matemático que foi treinado com dados para reconhecer padrões e fazer previsões. Na prática, um modelo é um arquivo (ou conjunto de arquivos) contendo pesos — números que foram ajustados durante o processo de treinamento para que o modelo produza respostas úteis.
Uma analogia que funciona bem: pense no modelo como um cérebro treinado para uma tarefa específica. Assim como um radiologista treinou anos lendo milhares de exames para identificar anomalias, um modelo de IA foi “treinado” processando milhões (ou bilhões) de exemplos para aprender padrões.
Tipos de modelos
| Tipo | O que faz | Exemplos |
|---|---|---|
| Linguagem | Gera e compreende texto, código, raciocínio | GPT-4o, Claude, Llama |
| Imagem | Gera, edita ou classifica imagens | DALL-E, Midjourney, Stable Diffusion |
| Áudio | Gera fala, transcreve áudio, clona vozes | Whisper, ElevenLabs, Bark |
| Multimodal | Combina texto, imagem, áudio e/ou vídeo | GPT-4o, Gemini 2.0, Claude 3.5 |
O que são parâmetros
Você já deve ter visto referências como “modelo de 7B” ou “modelo de 405B”. O B vem de billions (bilhões). Os parâmetros são os pesos internos do modelo — quanto mais parâmetros, maior a capacidade do modelo de capturar nuances e padrões complexos.
ℹ️ Informação: Mais parâmetros não significa necessariamente melhor. Um modelo de 70B bem treinado e otimizado pode superar um de 405B em tarefas específicas. O que importa é a combinação de arquitetura, dados de treinamento, técnica de otimização e alinhamento.
Na prática, modelos maiores (centenas de bilhões de parâmetros) são mais caros para rodar, mais lentos nas respostas e exigem infraestrutura robusta. Modelos menores (7B a 14B) podem rodar localmente em uma GPU de consumo e são ideais para tarefas específicas quando afinados (fine-tuned) para um domínio.
Treinamento vs. Inferência
- Treinamento: O processo de alimentar o modelo com dados para que ele aprenda padrões. É caro, demorado e feito por grandes empresas (OpenAI, Google, Meta). Pode levar semanas rodando em milhares de GPUs.
- Inferência: O processo de usar o modelo já treinado para gerar respostas. É o que acontece quando você envia uma mensagem ao ChatGPT — o modelo faz inferência para produzir a resposta.
Quando você usa uma API de IA (OpenAI, Anthropic, Google), você está pagando pela inferência. O custo é medido em tokens — unidades de texto processadas pelo modelo.
O que é LLM (Large Language Model)
LLM (Large Language Model, ou Modelo de Linguagem de Grande Escala) é um tipo específico de modelo de IA treinado em enormes volumes de texto. A ideia central é simples: o modelo aprendeu a prever a próxima palavra (mais precisamente, o próximo token) em uma sequência de texto.
Parece trivial, mas essa capacidade de prever o próximo token de maneira sofisticada é o que permite a um LLM:
- Gerar texto coerente — artigos, resumos, emails, documentação
- Escrever e explicar código — em dezenas de linguagens
- Traduzir entre idiomas
- Raciocinar sobre problemas — análise lógica, matemática, planejamento
- Seguir instruções — responder perguntas, executar tarefas complexas via prompt
Como funciona (simplificado)
Quando você envia uma pergunta a um LLM, o modelo não “entende” a pergunta no sentido humano. Ele calcula, com base nos padrões aprendidos durante o treinamento, qual sequência de tokens tem maior probabilidade de ser uma boa continuação para o texto que você enviou.
| |
É por isso que LLMs às vezes “alucinam” — ou seja, geram informações que parecem corretas mas são inventadas. O modelo está otimizado para gerar texto plausível, não necessariamente verdadeiro. Ele não consulta uma base de dados de fatos — ele gera texto baseado em padrões estatísticos.
Limitações importantes
| Limitação | Explicação |
|---|---|
| Alucinação | Inventa informações com aparência de verdade. Cita fontes que não existem, gera dados fictícios. |
| Corte de conhecimento | O modelo sabe apenas o que existia até a data final do treinamento. Não tem acesso a informações atuais. |
| Sem memória persistente | Cada conversa começa do zero (a menos que haja mecanismo externo de contexto). |
| Viés | Reflete vieses presentes nos dados de treinamento. |
| Janela de contexto | Há um limite de tokens que o modelo consegue processar de uma vez (4K, 128K, 200K, 1M — varia por modelo). |
⚠️ Atenção: Uma das armadilhas mais comuns para quem começa a usar LLMs é confiar demais na resposta. O modelo não “sabe” — ele gera texto que parece saber. Sempre valide informações críticas com fontes primárias.
Principais LLMs do mercado
| Modelo | Empresa | Destaques |
|---|---|---|
| GPT-4o, o1, o3 | OpenAI | Mais popular, excelente para uso geral e código |
| Claude 3.5 Opus/Sonnet | Anthropic | Forte em raciocínio longo, segurança e coding |
| Gemini 2.0 | Multimodal nativo, janela de contexto enorme | |
| Llama 3.3 | Meta | Open-source líder, executável localmente |
| DeepSeek V3, R1 | DeepSeek | Open-source, excelente custo-benefício |
O que é RAG (Retrieval-Augmented Generation)
Você acabou de aprender que LLMs têm um problema fundamental: eles não conhecem seus dados. O modelo foi treinado com dados públicos da internet, livros e código aberto — mas não sabe nada sobre a documentação interna da sua empresa, o wiki do seu time, seus contratos, seus logs, seus tickets.
RAG (Retrieval-Augmented Generation, ou Geração Aumentada por Recuperação) é a técnica que resolve esse problema sem precisar retreinar o modelo.
Como funciona
A ideia é elegante: antes de enviar a pergunta ao LLM, você busca informações relevantes em sua base de dados e as injeta no prompt como contexto adicional. O modelo então gera a resposta com base nesse contexto — não apenas no que ele aprendeu durante o treinamento.
| |
Por que RAG e não fine-tuning?
| Abordagem | Vantagem | Desvantagem |
|---|---|---|
| RAG | Dados sempre atualizados, sem custo de treinamento, mais transparente | Depende da qualidade da busca |
| Fine-tuning | Modelo internaliza o conhecimento, menor latência | Caro, dados ficam desatualizados, difícil de manter |
💡 Dica: Para a maioria dos casos de uso corporativo, RAG é a primeira opção. Fine-tuning só faz sentido quando você precisa que o modelo internalize um estilo, um vocabulário muito específico, ou quando a latência de busca é inaceitável.
Quando usar RAG
- Chatbots corporativos que respondem sobre documentação interna
- Assistentes de código que conhecem a base de código da sua empresa
- Sistemas de suporte que consultam manuais e FAQs
- Qualquer cenário onde o LLM precisa de informações que ele não tem por padrão
A chave do RAG é a busca vetorial — uma técnica que transforma texto em vetores numéricos (embeddings) e encontra documentos semanticamente similares à pergunta, mesmo que usem palavras diferentes.
O que é um Agente de IA
Um Agente de IA é um LLM com superpoderes: além de gerar texto, ele pode usar ferramentas, tomar decisões e executar ações de forma autônoma ou semi-autônoma.
A diferença entre um chatbot e um agente é a mesma diferença entre alguém que dá conselhos e alguém que faz as coisas acontecerem:
| Chatbot (LLM puro) | Agente de IA |
|---|---|
| “Você deveria criar um branch e abrir um PR.” | Cria o branch, escreve o código, abre o PR e pede sua revisão. |
| “A query SQL para isso seria SELECT…” | Executa a query, analisa os resultados e apresenta um relatório. |
| “Você pode corrigir o bug alterando a linha 42.” | Altera a linha 42, roda os testes, confirma que passam e faz o commit. |
O loop de um Agente
Um agente de IA funciona em um ciclo contínuo:
| |
Exemplos reais de Agentes
- GitHub Copilot Coding Agent: Recebe uma issue, cria um branch, implementa a solução, roda testes e abre um PR — tudo automaticamente.
- Agentes de CI/CD: Analisam falhas em pipelines, identificam a causa raiz e sugerem (ou aplicam) correções.
- Agentes de pesquisa: Recebem uma pergunta complexa, buscam em múltiplas fontes, sintetizam e entregam um relatório consolidado.
- Agentes de dados: Recebem uma pergunta em linguagem natural, traduzem para SQL, executam, analisam e apresentam resultados visuais.
⚠️ Atenção: Agentes são poderosos, mas trazem riscos. Um agente com permissões para executar comandos no terminal pode causar danos reais se mal configurado. Autonomia sem supervisão é o principal risco. Por isso, padrões como human-in-the-loop (aprovação humana antes de ações críticas) são fundamentais em ambientes de produção.
O que um Agente precisa
Para funcionar, um agente precisa de:
- Um LLM como “cérebro” (GPT-4o, Claude, Gemini, etc.)
- Ferramentas que ele pode invocar (APIs, CLI, buscadores, bancos de dados)
- Contexto (instruções, documentação, histórico da conversa)
- Permissões controladas (o que ele pode e o que não pode fazer)
- Um protocolo para conectar tudo (é aqui que entra o MCP — que veremos adiante)
O que é uma Skill
No ecossistema de agentes, uma Skill (habilidade) é um bloco de conhecimento ou instrução especializada que um agente pode consultar para realizar uma tarefa de forma mais precisa.
Pense assim: se o agente é um profissional generalista, a skill é o manual de referência que ele consulta quando precisa de conhecimento específico sobre um domínio.
Skill vs. Tool — qual a diferença?
Essa distinção é importante porque os dois termos aparecem frequentemente juntos:
| Conceito | O que é | Analogia |
|---|---|---|
| Skill | Conhecimento, instruções, boas práticas | Um manual de referência, um guia de estilo |
| Tool | Uma ação que o agente pode executar | Um martelo, uma chave de fenda, uma API |
Exemplo concreto no GitHub Copilot:
- Uma Skill de deploy Azure contém instruções sobre como estruturar arquivos Bicep, quais convenções seguir, quais erros evitar. O agente lê essas instruções para tomar melhores decisões.
- Uma Tool de terminal permite que o agente execute comandos no shell. Ele pode usar a skill de Azure para saber o que executar e a tool de terminal para executar de fato.
Exemplos de Skills
- Instruções de um projeto: Um arquivo
.instructions.mdque ensina ao Copilot as convenções do seu repositório (estilo de commit, estrutura de diretórios, padrões de código). - Domínios especializados: Skills de segurança (
azure-security), de deploy (azure-deploy), de avaliação de agentes (evaluation). - Conhecimento corporativo: Regras de negócio, políticas de compliance, padrões de arquitetura internos que o agente deve seguir.
💡 Dica: Skills são a forma mais acessível de personalizar um agente sem alterar o modelo. Em vez de fine-tuning (caro e complexo), você escreve instruções claras e o agente as segue. É a diferença entre treinar um funcionário novo do zero e entregar um manual bem escrito para ele consultar.
O que é MCP (Model Context Protocol)
O Model Context Protocol (MCP) é um protocolo aberto criado pela Anthropic que padroniza a forma como modelos de IA se conectam a ferramentas, dados e serviços externos.
O problema que o MCP resolve
Antes do MCP, cada ferramenta de IA tinha sua própria forma de integração. Se você quisesse que o Claude acessasse seu banco de dados, precisava de uma integração específica para o Claude. Se quisesse que o GPT acessasse o mesmo banco, precisava de outra integração. Era como se cada fabricante de eletrônico tivesse seu próprio tipo de conector — sem padrão, sem interoperabilidade.
A analogia do USB
O MCP faz para a IA o que o USB fez para dispositivos eletrônicos: define um padrão universal de conexão.
| |
Com MCP, você cria um servidor que expõe as ferramentas, e qualquer cliente compatível com MCP pode usá-lo. Desenvolva uma vez, conecte em qualquer lugar.
Componentes do MCP
| Componente | Função | Exemplo |
|---|---|---|
| MCP Server | Expõe ferramentas e dados via protocolo padronizado | Um server que fornece acesso a issues do GitHub |
| MCP Client | Consome as ferramentas expostas pelo server | VS Code, Claude Desktop, Cursor |
| Protocolo | Comunicação JSON-RPC entre client e server | Baseado em JSON-RPC 2.0 |
Exemplo prático
Imagine que sua empresa cria um MCP Server que expõe:
- Consulta a tickets no Jira
- Busca na documentação interna (wiki)
- Leitura de métricas do Grafana
Uma vez que esse MCP Server existe, qualquer agente de IA compatível com MCP pode usar essas ferramentas — seja o Copilot no VS Code, o Claude Desktop, ou um agente customizado da sua empresa.
Quem está adotando
O MCP foi criado pela Anthropic, mas a adoção rápida surpreendeu até os criadores:
- Microsoft: Integrou MCP no VS Code, GitHub Copilot e Azure AI
- Google: Suporte em Gemini e ferramentas Google Cloud
- Cursor: Suporte nativo a MCP Servers
- Comunidade: Centenas de MCP servers open-source (GitHub, Postgres, Slack, Notion, etc.)
ℹ️ Informação: O MCP é open-source e a especificação está disponível publicamente. Qualquer pessoa pode criar um MCP Server para expor ferramentas e dados, ou criar um MCP Client para consumi-los. Isso é o que torna o protocolo tão poderoso — ele é um padrão aberto, não proprietário.
Principais Players de IA no Mercado
Agora que você entende os conceitos, vamos mapear quem faz o quê no ecossistema de IA. Cada empresa tem pontos fortes diferentes — saber disso ajuda a escolher a ferramenta certa para cada cenário.
| Player | Principais Modelos | Destaque | Modelo de negócio |
|---|---|---|---|
| OpenAI | GPT-4o, o1, o3, DALL-E | Pioneira no hype de IA generativa. ChatGPT é o produto de IA mais popular do mundo. Forte em geração de código e uso geral. | API paga (por token), ChatGPT Plus ($20/mês) |
| Anthropic | Claude Opus, Sonnet, Haiku | Foco em segurança e alinhamento. Claude se destaca em raciocínio longo, análise de documentos extensos e coding. Criadora do MCP. | API paga, Claude Pro ($20/mês) |
| Gemini 2.0, Gemma | Multimodal nativo (texto + imagem + vídeo + áudio). Janela de contexto enorme (até 2M tokens). Integração com ecossistema Google. | API paga, Gemini Advanced ($20/mês) | |
| Meta | Llama 3.1, 3.3, 4 | Líder em modelos open-source. Llama pode ser baixado e executado localmente, sem depender de API. Ideal para quem quer controle total. | Open-source (gratuito para uso) |
| Microsoft | Copilot, Azure OpenAI | Não cria modelos próprios (usa OpenAI), mas lidera na integração enterprise. Copilot está no VS Code, GitHub, Office 365, Azure. | Licenças corporativas, Azure pay-as-you-go |
| DeepSeek | DeepSeek V3, R1 | Empresa chinesa que surpreendeu com modelos open-source de altíssima qualidade a custo muito baixo. Destaque em raciocínio e código. | Open-source + API a preços muito agressivos |
| Mistral | Mistral Large, Codestral | Empresa francesa. Modelos open-weight com foco em eficiência. Bom equilíbrio entre qualidade e custo. Forte em código. | Open-weight + API paga |
| xAI | Grok 2, Grok 3 | Empresa de Elon Musk. Integrado ao X (ex-Twitter). Foco em raciocínio e análise em tempo real. | API paga, integrado ao X Premium |
| Amazon | Nova, Bedrock | Amazon Bedrock é um hub multi-modelo (acessa Claude, Llama, Mistral via mesma API). Nova é o modelo próprio da Amazon. | AWS pay-as-you-go |
Como escolher
A escolha do player (e do modelo) depende do seu cenário:
- Uso geral e produtividade: OpenAI (ChatGPT) ou Google (Gemini) — são os mais acessíveis e versáteis.
- Desenvolvimento de software: Anthropic (Claude Sonnet) ou OpenAI (GPT-4o) — dominam em coding e raciocínio técnico.
- Privacidade e controle: Meta (Llama) ou Mistral — modelos open-source que rodam na sua infraestrutura.
- Custo agressivo: DeepSeek — qualidade competitiva a preços muito abaixo do mercado.
- Enterprise e integração: Microsoft (Azure OpenAI + Copilot) ou Amazon (Bedrock) — quando o ecossistema corporativo importa mais que o modelo em si.
- Multimodal avançado: Google (Gemini) — melhor em processamento combinado de texto, imagem e vídeo.
📝 Exemplo: Se você precisa de um chatbot interno para responder perguntas sobre documentação da empresa (cenário RAG), a escolha mais pragmática seria: Claude Sonnet (melhor custo-benefício em raciocínio) via Azure OpenAI ou Bedrock (se já usa AWS/Azure) com um MCP Server para acessar suas fontes de dados.
Como Tudo se Conecta
Agora que você conhece cada peça, veja como elas se encaixam no ecossistema moderno:
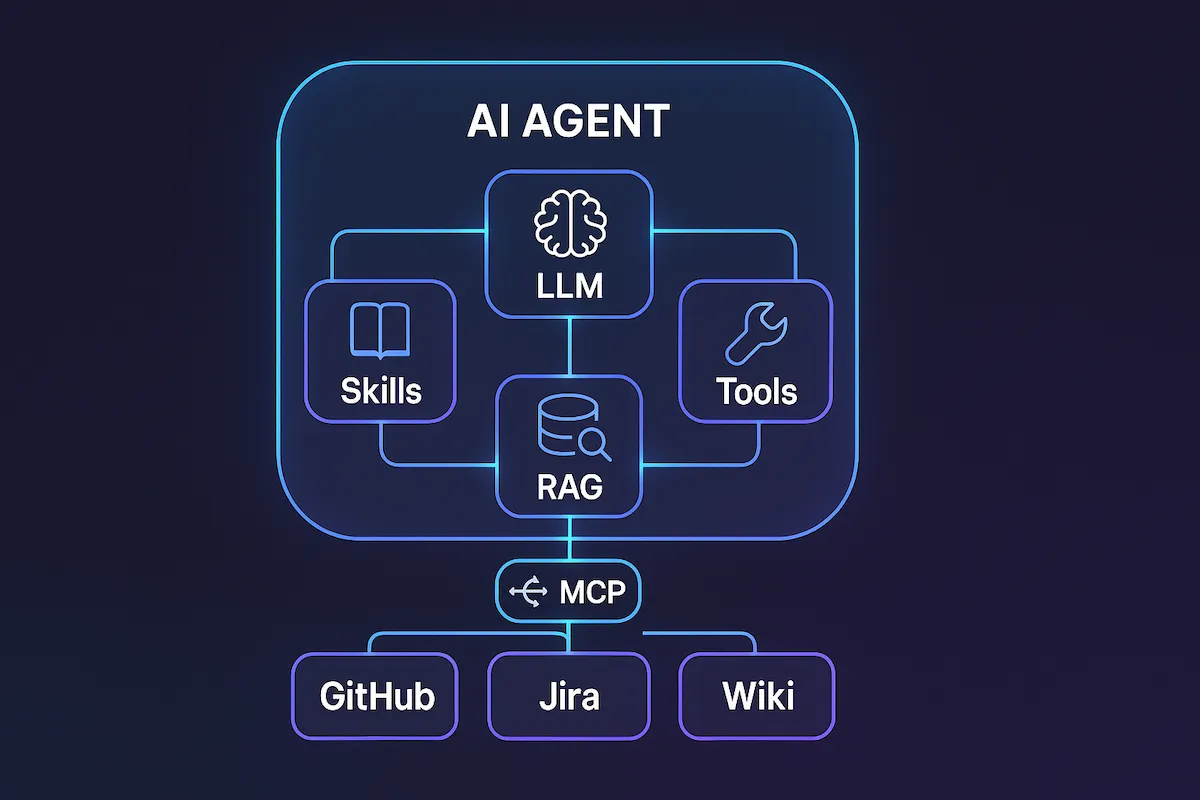
O LLM é o cérebro. As Skills dão conhecimento especializado. O RAG fornece dados atualizados. As Tools permitem ações reais. O MCP conecta tudo com um protocolo padronizado. E o Agente orquestra cada peça para completar tarefas complexas de forma autônoma.
Dicas e Boas Práticas
Se você está começando a trabalhar com IA no seu dia a dia profissional, aqui vão recomendações práticas:
Comece pelo que resolve um problema real. Não adote IA por hype. Identifique uma dor concreta do seu time — documentação desatualizada, respostas repetitivas em suporte, code reviews demorados — e aplique IA nesse ponto específico.
Não confie cegamente nos outputs de LLMs. Trate a saída do modelo como um rascunho de um estagiário competente: geralmente útil, às vezes brilhante, mas sempre precisa de revisão por alguém que entende do assunto.
Entenda o custo antes de integrar. APIs de IA cobram por token. Uma integração mal projetada pode gerar contas altas rapidamente. Monitore consumo, defina limites e use modelos menores quando a tarefa permitir.
RAG antes de fine-tuning. Se o problema é que o LLM não conhece seus dados, comece com RAG. Fine-tuning é caro, difícil de manter e raramente necessário para casos de uso corporativos.
Adote MCP para integrações. Se você vai conectar um agente a ferramentas internas, use MCP. Criar integrações proprietárias é dívida técnica — o protocolo padronizado facilita manutenção e permite trocar o modelo sem refazer as integrações.
Skills são baratas e poderosas. Antes de investir em soluções complexas de customização, tente escrever instruções claras (skills) para o agente. Um bom prompt com contexto bem definido resolve mais do que um fine-tuning malfeito.
Autonomia de agentes exige governança. Antes de dar permissões de escrita a um agente (executar comandos, modificar arquivos, abrir PRs), defina políticas de aprovação e limites claros. Human-in-the-loop não é burocracia — é segurança.
Conclusão
A sopa de siglas da IA pode parecer intimidante, mas cada conceito tem um papel claro e bem definido. IA é o campo amplo. Modelos são os cérebros treinados. LLMs são os modelos de linguagem que geram texto e código. RAG resolve o problema de dados que o LLM não conhece. Agentes adicionam autonomia e capacidade de ação. Skills fornecem conhecimento especializado. E MCP conecta tudo com um protocolo aberto e padronizado.
O ecossistema de IA não é mais um experimento de laboratório — é uma realidade que já está em ferramentas que profissionais de TI usam diariamente (Copilot, ChatGPT, Claude, Gemini). Entender os conceitos fundamentais não é opcional: é o que separa quem usa a ferramenta de quem entende a ferramenta. E quem entende, usa melhor.
Minha recomendação: não tente aprender tudo de uma vez. Escolha um conceito deste artigo que se aplica ao seu trabalho agora — talvez RAG para um chatbot interno, talvez MCP para padronizar integrações, talvez simplesmente entender melhor como o LLM que você já usa funciona por baixo dos panos — e aprofunde-se nele. O conhecimento prático se constrói uma peça de cada vez.
Se quiser se aprofundar em como a IA está impactando especificamente a carreira de desenvolvedores, recomendo a leitura do artigo abaixo. E se tiver dúvidas ou quiser discutir algum conceito, os comentários estão abertos.
Leia Também
- A IA Vai Substituir Desenvolvedores? Opinião Honesta — Uma análise detalhada sobre o impacto real da IA generativa na carreira de desenvolvedores.
- GitHub Copilot: Agentes de IA, Modelos e Guia Completo — Tudo sobre os agentes de IA e modelos do GitHub Copilot: quais são, quando usar cada um e como funciona o consumo de tokens.
Referências
- OpenAI — GPT-4o Documentation — Documentação oficial dos modelos da OpenAI, incluindo capabilities e limites.
- Anthropic — Claude Model Card — Especificações técnicas, janelas de contexto e diferenças entre Opus, Sonnet e Haiku.
- Model Context Protocol — Specification — Especificação oficial do MCP, com guias de implementação para servers e clients.
- Google — Gemini API Documentation — Documentação do Gemini, incluindo recursos multimodais e limites de tokens.
- Meta — Llama Models — Página oficial dos modelos Llama, com links para download e documentação de uso.
- Microsoft — Azure AI Services — Documentação do ecossistema de IA da Microsoft, incluindo Azure OpenAI e Copilot Stack.
- Lewis, P. et al. — Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020) — Paper original que introduziu o conceito de RAG.
Ao comentar, você concorda com nossa Política de Privacidade, Termos de Uso e Política de Exclusão de Dados.