
Introdução
Se você trabalha com .NET e EF Core em aplicações corporativas, já encontrou cenários onde precisa gravar, atualizar ou remover milhares de registros de uma só vez. O EF Core padrão executa uma operação SQL para cada entidade no ChangeTracker — para 10.000 registros, isso são 10.000 roundtrips ao banco. Em aplicações de médio e grande porte, isso é inaceitável.
A biblioteca EFCore.BulkExtensions resolve esse problema de forma elegante, usando operações nativas de cada banco de dados (como MERGE no SQL Server ou INSERT ... ON CONFLICT no PostgreSQL) para processar milhares de registros em uma única operação.
Neste artigo, você vai conhecer:
- Quem mantém o projeto e a relação com o ecossistema .NET
- O erro clássico de tracking que 90% dos desenvolvedores cometem (e culpam o EF Core)
- Por que o EF Core se comporta assim — e por que está correto
- Todos os 8 métodos da biblioteca com exemplos reais
- Integração com Azure Service Bus para processamento em alto volume
Pré-requisitos: Familiaridade com C# e EF Core. Recomenda-se ter lido os artigos sobre Fluent API e mapeamento com EF Core e gargalos de banco de dados com mensageria antes de continuar.
📦 Código-fonte: A implementação completa deste artigo está no repositório blog-zocateli-sample no GitHub. Clone, explore e adapte ao seu contexto.
O Projeto EFCore.BulkExtensions
História e Manutenção
O EFCore.BulkExtensions é mantido por Boris Djurdjevic (@borisdj), um engenheiro de software sênior da Sérvia especializado em acesso a dados e performance de banco de dados. O projeto foi criado em 2017 e rapidamente se tornou a biblioteca de operações bulk mais popular do ecossistema .NET.
Números do projeto (março/2026):
| Métrica | Valor |
|---|---|
| ⭐ Stars no GitHub | 3.700+ |
| 📦 Downloads NuGet | 30 milhões+ |
| 🧑💻 Contribuidores | 70+ |
| 📋 Issues resolvidas | 900+ |
| 🔄 Releases | 100+ |
| 📄 Licença | MIT |
Relação com o Time do EF Core e .NET Foundation
É importante esclarecer: Boris Djurdjevic não é membro do time do Entity Framework Core da Microsoft, nem o projeto EFCore.BulkExtensions é um projeto oficial da .NET Foundation. Trata-se de um projeto independente da comunidade open-source, licenciado sob MIT.
No entanto, o projeto mantém compatibilidade rigorosa com cada versão do EF Core (3.x, 5.x, 6.x, 7.x, 8.x) e é amplamente reconhecido pela própria Microsoft em discussões sobre performance. Vários contribuidores do repositório possuem experiência profissional com SQL Server, PostgreSQL e Oracle — o que explica a qualidade do suporte multi-provider.
Provedores de Banco Suportados
| Provider | Estratégia Bulk |
|---|---|
| SQL Server | SqlBulkCopy + MERGE (melhor performance) |
| PostgreSQL | COPY + INSERT ... ON CONFLICT |
| MySQL | LOAD DATA + INSERT ... ON DUPLICATE KEY |
| SQLite | INSERT OR REPLACE |
| Oracle | Via provider adaptado |
A biblioteca detecta automaticamente o provider configurado no DbContext e usa a estratégia nativa mais eficiente.
O Erro Clássico: Delete → ReInsert e o ChangeTracker
![]()
O Cenário
Um cenário extremamente comum em aplicações corporativas: você precisa sincronizar dados de uma fonte externa (CSV, API, outro sistema). A abordagem “intuitiva” de muitos desenvolvedores é:
- Buscar todos os registros existentes
- Remover todos
- Inserir os novos
| |
O Erro
| |
Por Que Acontece
O ChangeTracker do EF Core é um mapa de identidade em memória. Quando você faz ToListAsync(), todas as entidades retornadas são rastreadas com estado Unchanged. Ao chamar RemoveRange(), o estado muda para Deleted. Quando o SaveChangesAsync executa, as entidades são removidas do banco, mas o ChangeTracker ainda mantém referências dessas entidades com o mesmo Id.
Se algum registro novo tiver o mesmo Id de um registro que acabou de ser removido, o EF Core detecta a colisão e lança a exceção. Mesmo que o registro já tenha sido deletado do banco, a identidade em memória ainda existe no contexto.
A Solução com EF Core Puro
| |
O ChangeTracker.Clear() descarta todas as referências rastreadas, permitindo que novas entidades com os mesmos Ids sejam adicionadas sem conflito.
EF Core Não Foi Projetado Para Isso
Antes de culpar o EF Core, entenda quem está por trás da ferramenta. O time que mantém o Entity Framework Core não é composto apenas por desenvolvedores — são engenheiros de dados, arquitetos de banco de dados e especialistas com experiência direta em fornecedores como Oracle, SQL Server e PostgreSQL. Nomes como Arthur Vickers, Shay Rojansky (mantenedor do Npgsql) e Brice Lambson contribuíram diretamente para o EF Core com décadas de experiência em mecanismos de banco de dados.
Se o EF Core se comporta de determinada forma por padrão — como manter o tracking ativo e impedir que duas instâncias com o mesmo Id coexistam no mesmo contexto — não é um bug. É uma decisão arquitetural fundamentada em princípios de integridade de dados e concorrência otimista.
O Propósito do EF Core
O EF Core foi projetado para ser um ORM transacional focado em:
- Unit of Work: agrupa mudanças relacionadas em uma transação atômica
- Identity Map: garante que cada registro no banco tenha no máximo uma representação em memória
- Concorrência otimista: detecta conflitos entre operações concorrentes
- OLTP (processamento transacional): insere, atualiza e remove registros individuais ou em pequenos lotes com segurança transacional
O padrão do EF Core é rastrear entidades porque a maioria dos cenários (APIs REST, CRUD, e-commerce) opera sobre dezenas de registros por requisição, não milhares.
A Abordagem Correta Para Sincronização em Massa
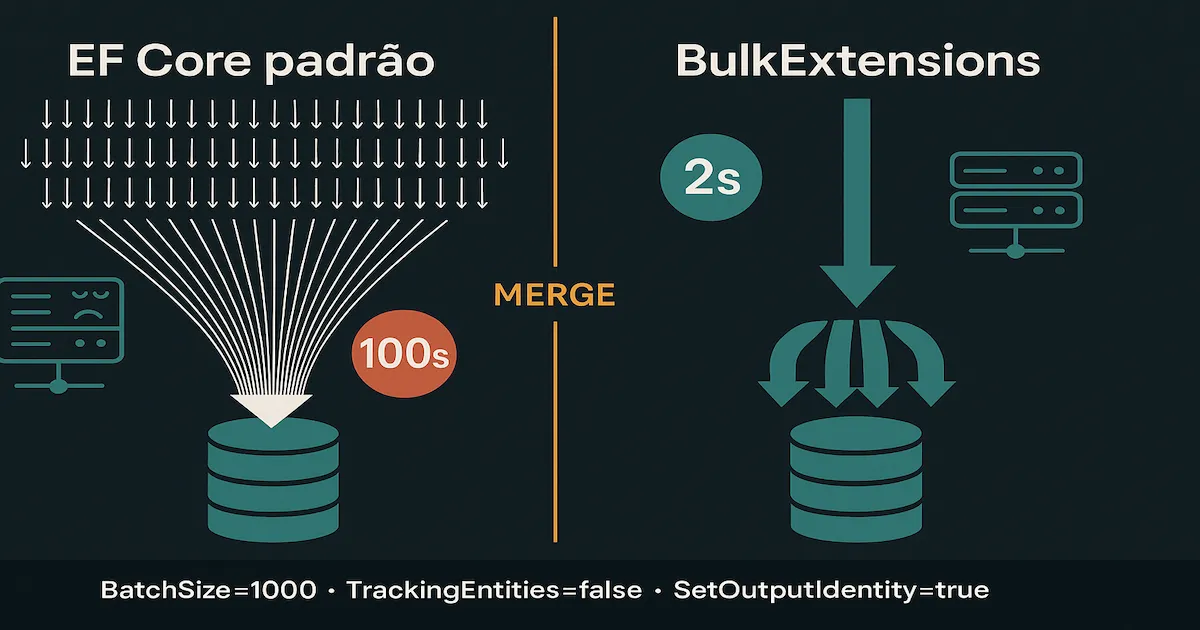
Quando o cenário exige processar milhares de registros — sincronização de inventário, importação de CSV, ingestão de dados de filas — você está fora do escopo do EF Core padrão. É aqui que o EFCore.BulkExtensions entra.
Em vez de Delete + ReInsert, a abordagem correta é um UPSERT (INSERT or UPDATE):
| |
Essa abordagem:
- Não precisa buscar os registros existentes primeiro
- Não acessa o ChangeTracker
- Executa um
MERGEnativo no SQL Server (ouINSERT ... ON CONFLICTno PostgreSQL) - Processa 10.000 registros em ~2 segundos (vs. ~100 segundos com EF Core puro)
Se você precisa além do UPSERT — remover registros que não existem mais na fonte — use BulkInsertOrUpdateOrDeleteAsync (seção 5 abaixo).
Instalação e Configuração
Instalação via NuGet
| |
A biblioteca detecta automaticamente o provider do EF Core configurado. Para SQL Server, nenhuma configuração adicional é necessária. Para PostgreSQL, certifique-se de que o Npgsql está instalado.
| |
Compatibilidade
| EF Core | BulkExtensions | .NET |
|---|---|---|
| 8.x | 8.x | .NET 8+ |
| 7.x | 7.x | .NET 7+ |
| 6.x | 6.x | .NET 6+ |
Dica: Use sempre a mesma major version do EFCore.BulkExtensions que seu EF Core. Exemplo: EF Core
8.0.13→ BulkExtensions8.1.3.
Namespace
| |
Todos os métodos são extension methods do DbContext — não é necessário herdar de nenhuma classe especial.
Todos os Métodos com Exemplos Reais
A seguir, os 8 métodos principais da biblioteca com exemplos reais usando as entidades RegistroApp, ClienteApp e ConfiguracaoSegura do repositório blog-zocateli-sample.
1. BulkInsertAsync — INSERT em Massa
Insere milhares de registros usando SqlBulkCopy (SQL Server) ou COPY (PostgreSQL). Zero interação com o ChangeTracker.
| |
Quando usar: Carga inicial de dados, importação de CSV, dados obtidos em um banco diferente, ingestão de eventos.
2. BulkUpdateAsync — UPDATE em Massa
Atualiza registros existentes por chave primária. Você pode escolher quais propriedades atualizar.
| |
Quando usar: Atualizar status em lote, flags de processamento, campos calculados.
3. BulkDeleteAsync — DELETE em Massa
Remove registros por chave primária sem carregar as entidades primeiro.
| |
Quando usar: Exclusão periódica de dados expirados, limpeza de registros órfãos, purge de dados antigos.
4. BulkInsertOrUpdateAsync — UPSERT (MERGE)
O método mais poderoso da biblioteca. Executa um MERGE no SQL Server — insere registros novos e atualiza existentes em uma única operação.
| |
Quando usar: Sincronização com fonte externa (API, CSV, Azure DevOps, Dados de outro banco), ingestão de mensagens de filas.
5. BulkInsertOrUpdateOrDeleteAsync — Sincronização Completa
Faz tudo que o UPSERT faz, mas também remove registros que existem no banco e não existem na lista fornecida. É a sincronização delta completa.
| |
Quando usar: Sync total com sistema master, espelhamento de catálogos, mirror de repositórios Azure DevOps.
⚠️ Cuidado: Este método remove do banco tudo que não estiver na lista. Use com sabedoria e sempre em contexto transacional.
6. BulkSaveChangesAsync — Substituto do SaveChangesAsync
Se você já usa o padrão Add/Update/Remove com o ChangeTracker, pode simplesmente trocar SaveChangesAsync() por BulkSaveChangesAsync() para ganhar performance sem mudar a lógica.
| |
Quando usar: Migração gradual de código existente — troque SaveChangesAsync por BulkSaveChangesAsync sem refatoração.
7. BulkReadAsync — Leitura em Lote por Chave
Carrega registros em massa por chave primária ou chave composta. Evita N+1 queries quando você precisa buscar entidades antes de um update em lote.
| |
Quando usar: Pré-carregar entidades para comparação antes de um update seletivo, validar existência em lote.
8. TruncateAsync — TRUNCATE TABLE
Executa TRUNCATE TABLE nativo. Diferente do DELETE sem WHERE, o truncate:
- Não gera log de transação por registro (minimal logging)
- Redefine identity/sequence para o valor inicial
- É significativamente mais rápido que delete em tabelas grandes
| |
Quando usar: Limpeza de tabelas de staging, reset de dados de teste, recarga completa de cache em banco.
⚠️ Cuidado:
TRUNCATEnão pode ser filtrado e não dispara triggers. Use apenas em tabelas que podem ser limpas completamente.
BulkConfig: O Coração da Biblioteca
O BulkConfig é a classe de configuração que controla o comportamento de todas as operações bulk. Aqui estão as propriedades mais importantes:
| Propriedade | Tipo | Descrição |
|---|---|---|
BatchSize | int | Registros por lote SQL. Padrão: 2000. Recomendado: 500-2000. |
SetOutputIdentity | bool | Retorna IDs gerados pelo banco (identity/sequence) nos objetos da lista. |
PreserveInsertOrder | bool | Garante que a ordem da lista original é respeitada no INSERT. |
UpdateByProperties | List<string> | Propriedades usadas como chave para Match no MERGE/UPSERT. |
PropertiesToIncludeOnUpdate | List<string> | Whitelist: apenas estas propriedades serão atualizadas. |
PropertiesToExcludeOnUpdate | List<string> | Blacklist: estas propriedades não serão atualizadas. |
TrackingEntities | bool | Se false, não atualiza o ChangeTracker após a operação. Sempre use false para performance. |
UseTempDB | bool | SQL Server: usa tempdb para staging. Útil quando há restrições de permissão. |
SqlBulkCopyOptions | SqlBulkCopyOptions | Opções nativas do SqlBulkCopy (ex: KeepIdentity, CheckConstraints). |
Exemplo de BulkConfig Completo (Cenário Real)
Este é o padrão usado em produção para sincronizar registros de inventário de aplicações — baseado em um projeto real de gestão de inventário corporativo:
| |
Exemplo Real: Inventário de Aplicações
Para demonstrar o poder da biblioteca em cenário enterprise, vamos ver como um sistema de inventário corporativo usa BulkInsertOrUpdateAsync para sincronizar dados de centenas de repositórios Azure DevOps.
O Cenário
Uma empresa precisa manter um inventário atualizado de todas as suas aplicações: projetos, repositórios, linguagens, versões de framework e secrets do Azure Key Vault. Um Worker Service é executado periodicamente para:
- Consultar a API do Azure DevOps e listar todos os repositórios
- Para cada repositório, extrair metadados (linguagem, framework, etc.)
- Sincronizar no banco via
BulkInsertOrUpdateAsync
O Repositório
| |
O Mesmo Padrão para Secrets
| |
Observe que o padrão é idêntico para diferentes entidades — o que muda são as propriedades de UpdateByProperties (chave composta para o MERGE) e PropertiesToExcludeOnUpdate (campos protegidos).
Integração com Azure Service Bus para Alto Volume
Quando o volume de dados é realmente alto — dezenas de milhares de registros chegando em rajada — a melhor prática é combinar mensageria com operações bulk. Conforme explorei em detalhes no artigo Gargalo em Banco de Dados: Mensageria e Paginação, a mensageria (Azure Service Bus ou RabbitMQ) serve como buffer entre o produtor de dados e o banco, permitindo que o Worker consuma em lotes otimizados.
O Padrão: Service Bus + BulkInsertOrUpdate
O fluxo é:
| |
- O produtor envia mensagens para a fila (uma por registro)
- O Worker consome até N mensagens por vez (
ReceiveMessagesAsync) - Converte as mensagens em entidades de domínio
- Persiste em massa via
BulkInsertOrUpdateAsync - Confirma as mensagens processadas com
CompleteMessageAsync
Implementação
| |
Por Que Funciona em Alto Volume
| Sem BulkExtensions | Com BulkExtensions |
|---|---|
| 10.000 INSERT individuais | 1 BulkInsertOrUpdate com BatchSize = 1000 |
| ~100s (10ms × 10.000) | ~2-3s |
| 10.000 transações | 10 transações (10 batches de 1.000) |
| ChangeTracker com 10.000 entidades | Zero ChangeTracker |
Para se aprofundar em Workers e Background Services para alto volume, leia o artigo .NET Worker e Background Service: Alto Volume.
Quando Usar (e Quando Não Usar) BulkExtensions
✅ Use Quando
- Carga inicial de dados (seed, migração, ETL)
- Sincronização periódica com API externa (Azure DevOps, SAP, Outros Bancos, etc.)
- Processamento de filas (Azure Service Bus, RabbitMQ) com alto volume
- Importação de CSV/Excel com milhares de linhas
- Atualização de status em lote (flags, campos calculados)
- Limpeza periódica de dados expirados
❌ Não Use Quando
- CRUD simples de poucos registros por requisição (o EF Core padrão é suficiente)
- Operações que precisam de validação individual por registro com regras de negócio complexas
- Cenários onde o ChangeTracker é necessário para auditoria ou eventos de domínio
- Tabelas com triggers complexos que precisam ser disparados por registro
Alternativas Nativas do EF Core 8+
O EF Core 8 introduziu ExecuteUpdate e ExecuteDelete que executam diretamente no banco sem passar pelo ChangeTracker:
| |
Essas alternativas são boas para updates/deletes condicionais, mas não substituem BulkInsertAsync, BulkInsertOrUpdateAsync nem BulkReadAsync — operações que o EF Core nativo não oferece.
Conclusão
O EFCore.BulkExtensions é, sem dúvida, uma das bibliotecas mais importantes do ecossistema .NET. Com mais de 30 milhões de downloads e uma API consistente, ela preenche uma lacuna real do EF Core: operações em massa com performance nativa de banco.
Antes de culpar o EF Core por erros de tracking ou performance, entenda o propósito da ferramenta — ela foi construída por engenheiros de dados que conhecem profundamente SQL Server, PostgreSQL e Oracle. Se o comportamento padrão parece “errado”, provavelmente é o cenário que está fora do escopo.
Pontos-chave:
- O erro de tracking (delete + reinsert) é do desenvolvedor, não do EF Core — use
ChangeTracker.Clear()ou, melhor,BulkInsertOrUpdateAsync - TrackingEntities = false deve ser o padrão em operações bulk
- UpdateByProperties define a chave lógica do MERGE — não precisa ser a PK
- PropertiesToExcludeOnUpdate protege campos como Id e CriadoEm de serem sobrescritos
- Combinado com Azure Service Bus, o padrão de consumo em lote + persist bulk é imbatível para alto volume
📦 Código-fonte: blog-zocateli-sample — DataAccess/BulkOperations
Ao comentar, você concorda com nossa Política de Privacidade, Termos de Uso e Política de Exclusão de Dados.